
Fundamental refactoring vs elaborative refactoring
Two types of structure.
Historian Benedict Anderson once wrote that, "All communities larger than primordial villages of face-to-face contact ... are imagined."
In a sense, both class dependencies and package dependencies, too, are imagined. They're not really there. And yet we expend vast energies in managing them. What motivates us to grapple with hallucinatory monsters?
Well, this blog's primary assumption is that source code structure matters because of money. Specifically, poorly structured software suffers heavily from ripple effects, whereby changing code in one place triggers changes in many others, all of which adds to gruesome update costs. Poorly structured software, furthermore, is so tangled that even predicting update costs is difficult because those ripple effects splatter everywhere.
Figure 1, for example, shows a good package structure on the left - where clear dependencies render update cost analysis unproblematic - and an unholy shambles of a package structure on the right.
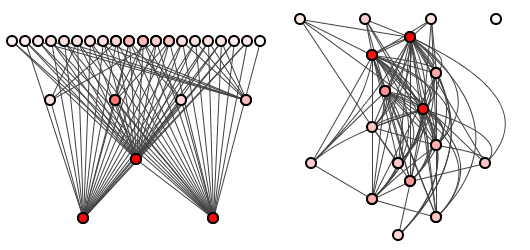
Figure 1: Two systems, two package structures.
If we are to examine the potential ripple effects of these specimens, we must understand how ripple effects flash from one place to another. Consider the chain of Java methods as follows, where a() calls b(), b() calls c(), etc:
private int a(int value) {
return b(value) * 2;
}
private int b(int value) {
return c(value) * 3;
}
private int c(int value) {
return d(value) * 5;
}
private int d(int value) {
int startValue = 7;
return value - startValue;
}
A ripple effect occurs when someone decides to change startValue to 13.5, a double, and decides that this precision must be preserved, thus requiring that a(), b() and c() be updated from ints to doubles.
private double d(double value) {
double startValue = 13.5;
return value - startValue;
}
Programmers shun long transitive dependencies because they have more methods for any random change to ripple back to.
Old news. Trivial. Nothing to see here.
Does this alter, however, when we examine class dependencies? Let's
snuggle a() and b() into one class and c()
and d() into another, still preserving the method-level
transitive dependency: a()  b()
c() d().
b()
c() d().
class Here {
There there = new There();
private int a(int value) {
return b(value) * 2;
}
private int b(int value) {
return there.c(value) * 3;
}
}
class There {
int c(int value) {
return d(value) * 5;
}
private int d(int value) {
int startValue = 7;
return value - startValue;
}
}
Again, consider that d() changes, triggering updates in all others. Does this example differ from the previous?
We know that transitive-dependency length is the enemy, and in this second example we have, on class-level, a shorter transitive dependency of just two classes. So are ripple effects less probable among these two classes than among the four methods of the first example?
No, they are not. Because the four methods are still there. The probability of ripple effects along those four methods remains unchanged. (McBain-voice) "The classes do nothing!"
What of package dependencies? Let's wrap these puppies in separate packages: would that help reduce the potential costs of ripple effects?
package x;
class Here {
There there = new There();
private int a(int value) {
return b(value) * 2;
}
private int b(int value) {
return there.c(value) * 3;
}
}
package y;
public class There {
public int c(int value) {
return d(value) * 5;
}
private int d(int value) {
int startValue = 7;
return value - startValue;
}
}
You see where this is going. Despite encapsulating the classes within two packages, there remains a pesky transitive dependency four methods long, and ripple effects fundamentally travel over method dependencies.
Yes, classes also suffer ripple effects. Above, class Here gets whacked because of the change in class There, but this is a consequence of the underlying method-level dependencies. No class-level dependency (and hence no class-level ripple effect) can exist without an underlying method-level dependency (presuming you don't access field variables directly, which you don't, right?).
From a ripple-effect point of view, class- and package-level dependencies are merely indicative aggregations of underlying method-level dependencies. It is in this sense that they do not exist, at least as independent constructs.
Thus method-level source code structure may be seen as fundamental structure, whereas class- and package-level structure may be seen as derived structure in that it derives from underlying method-level structure.
So can we just ignore this derived structure and go for a beer?
No. It simply serves a different and no less important purpose from fundamental structure.
Consider again the good and bad package structures of figure 1, reproduced here in figure 2 ... because scrolling.
Figure 2: figure 1 again.
If our theory is right, then neither of these derived package structures tells us about how much either system will cost to update, that information being frozen into the method-level structure.
If, however, we assume typical distributions of methods over packages (that is, no one package contains, say, 99% of all methods) then figure 2 tells us something important: it tells us that we can predict relative update costs for the beauty on the left better than for the beast on the right.
A change to an upper-most package of the left-hand-side system, we can predict, should cost less than a change to a package on the bottom, as there are far more dependencies on those lower packages. This is a huge benefit over the crayon scribble, in which changing any package might impact almost all others.
It is the derived structure - not the fundamental structure - that enables this coarse-grained predictability, essential for any large commercial software project.
You might suspect that this predictability also stems from the fundamental method structure, that the system on the left must derive from a better method structure than that on the right. But no. In fact, both package structures of figure 2 derive from identical method structures: they are actually the same system.
Figure 3 shows how evil hackers tortured the system on the left with
182 refactorings (using the brute-force package-coupling reducing
algorithm from a previous
post). The details are unimportant, but the algorithm merely moves
classes between packages, translations which have no effect whatsoever
on the method structure (consider our four methods above
where a() b()
c() d(); this
transitive dependency remains unchanged whether all four methods huddle
inside one class, or frolic in two, three or four classes or
packages).
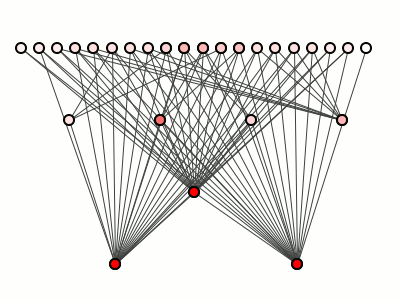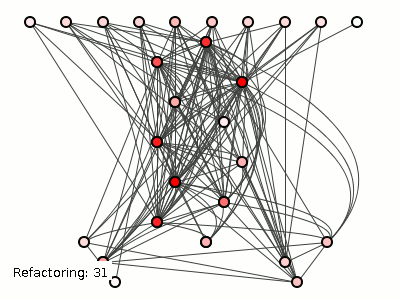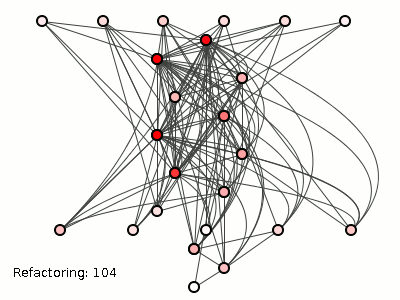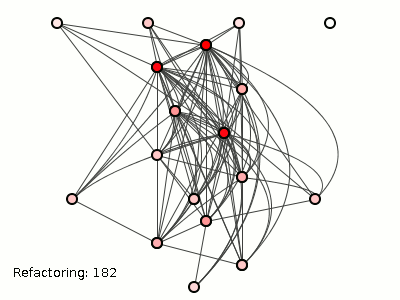
Figure 3: A good structure, pummeled to death.
Two types of refactoring.
Given these two different structures, and given that refactoring is simply behaviour-preserving re-structuring, it follows that there must be two types of refactoring.
If you change a program's fundamental structure - if, say, you add or merge methods, or if you prune long method transitive dependencies - then you are doing the first type of refactoring, let's call it: fundamental refactoring. The goal of fundamental refactoring is to make programs cheaper to update.
If you change a program's derived structure - if, say, you split a class in two, or move some classes to a new package - then you are doing the second type of refactoring, let's call it: elaborative refactoring. The goal of elaborative refactoring is not to make programs cheaper to update, but to make update costs more predictable (by "elaborating" the coarse-grained nature of the system).
It just so happens, that the way to improve both structures is the same: minimize the length of transitive dependencies, be they on method-, class- or package-level.
So in a sense, this is all rather philosophical.
So ... yeah ... sorry about that.
Summary.
The blog has screeched for some time that good structure can help both reduce update costs and improve cost-predictability.
Now you know how.